

2026/5/21 ・ langchain
langchain をなんとなく理解する
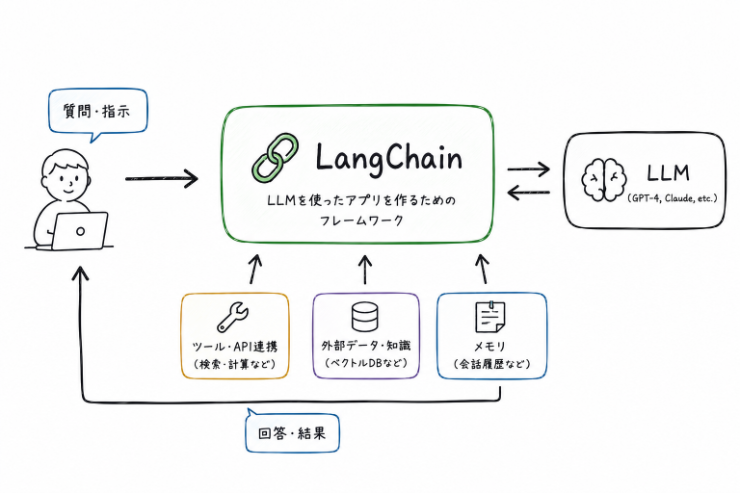
LangChain とは
LLM(大規模言語モデル)を使ったアプリケーションを作るための Python フレームワーク とのことです。
と言われてもあんまり良くわからなかったので実際に動かしていきます。
メモ書きをブログに乗せ直してるだけなので読みにくかったらごめんなさいね。
前提として
ChatGPT などの LLM 単体では「テキストを投げたら返ってくる」だけです。ただのチャットですね。
いや、ChatGPTはもっと色々できますね... まぁいいや。
LLM 単体に対しては基本的にチャットにしかならんのですが、LangChain を使うことで以下のようなことができるようになるっぽいです:
- 複数の処理を順番につなげる(チェーン)
- 外部データ(PDF・データベースなど)と組み合わせる
- LLM に道具(ツール)を持たせて自律的に動かす(エージェント)
- 会話の履歴を記憶させる
ユーザーの質問
→ プロンプトを整形
→ LLM に投げる
→ LLM が色々調べたりする
→ 結果を加工
→ 回答を返す
この一連の流れを部品として組み合わせて作れるのが LangChainとのこと。
とりあえず動かしましょ。
環境構築
uv init .
uv python pin 3.12
uv add langchain
ファイル運用
各ステップごとに別ファイルを作って残していきます。
最終的に以下の様な感じになるはず。
後から参照しやすい。
作業ディレクトリ/
├── pyproject.toml
├── step1_llm.py
├── step2_prompt.py
├── step3_chain.py
├── step4_parser.py
├── step5_memory.py
├── step6_tools.py
├── step7_agent.py
└── step8_rag.py
実行は uv run python step1_llm.py のようにファイル名を指定して実行すればいいと思います。
学習プラン
こんな感じの流れになりました。
Step7 と Step8 では googleのgeminiをちょっと使います。
ちょっとなので金はかからんです。
基本的にエラーがでなければ成功してるでいいと思います。
Step 1: LLM を呼び出す
Step 2: プロンプトテンプレート
Step 3: チェーン(LCEL)
Step 4: 出力パーサー
Step 5: メモリ
Step 6: ツール
Step 7: エージェント
Step 8: RAG
Step 1: LLM を呼び出す
ファイル: step1_llm.py
実行: uv run python step1_llm.py
FakeListChatModel を使って API キーなしで動作確認。
from langchain_core.language_models.fake_chat_models import FakeListChatModel
from langchain_core.messages import HumanMessage
llm = FakeListChatModel(responses=["こんにちは!"])
response = llm.invoke([HumanMessage(content="やあ")])
print(response.content)
invoke()に messages のリストを渡すと LLM がレスポンスを返すFakeListChatModelはresponsesに渡した文字列を順番に返すダミー LLM
Step 2: プロンプトテンプレート
ファイル: step2_prompt.py
実行: uv run python step2_prompt.py
プロンプトを毎回べた書きするのではなく、変数を埋め込んで使い回せるテンプレートとして定義する仕組み。
LLM 側の設定を変数で切り替えられる感じだと思ってます。
メッセージの種類
一応概念として抑えて置きたいところでうす。
チャット形式の LLM には3種類の発言があります:
| 種類 | 役割 |
|---|---|
| SystemMessage | LLM への役割・ルールの設定。会話の前提を定義する |
| HumanMessage | ユーザーからの発言 |
| AIMessage | LLM からの返答 |
SystemMessage : あなたは Python の先生です
HumanMessage : リストとは何ですか?
AIMessage : リストとは...(LLMの返答)
HumanMessage : もっと詳しく教えてください
AIMessage : ...
コード
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.language_models.fake_chat_models import FakeListChatModel
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは{language}の先生です。"),
("human", "{word}を説明してください。"),
])
llm = FakeListChatModel(responses=["説明します。"])
messages = prompt.invoke({"language": "Python", "word": "リスト"})
print(messages)
response = llm.invoke(messages)
print(response.content)
prompt.invoke()で変数を埋め込んだメッセージリストに変換される- そのメッセージリストを
llm.invoke()に渡してレスポンスを得る
Step 3: チェーン(LCEL)
ファイル: step3_chain.py
実行: uv run python step3_chain.py
| でコンポーネントをつなげて一連の処理を一発で実行できる書き方。LCEL(LangChain Expression Language)と呼ばれるようです。
コード
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.language_models.fake_chat_models import FakeListChatModel
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは{language}の先生です。"),
("human", "{word}を説明してください。"),
])
llm = FakeListChatModel(responses=["説明します。"])
chain = prompt | llm
response = chain.invoke({"language": "Python", "word": "リスト"})
print(response.content)
Step 2 では prompt.invoke() → llm.invoke() と2段階でしたが、chain.invoke() 一発で済みます。
チェーン内の処理を確認する
デバッグ用の機能があるので一応記載。
set_debug(True) を使うと各ステップの入出力が確認できます。
from langchain_core.globals import set_debug
set_debug(True)
set_verbose(True) という方法もあるようが、こちらは概要のみ表示で出力が少なかったです。学習中は set_debug の方が中身が見えてわかりやすいと思う。
| set_debug | set_verbose | |
|---|---|---|
| 出力量 | 多い(全ステップの入出力) | 少ない(概要のみ) |
| 学習向き | ✅ | △ |
Step 4: 出力パーサー
ファイル: step4_parser.py
実行: uv run python step4_parser.py
LLM の出力を自動で加工する仕組み。チェーンの末尾に | でつなげて使います。
StrOutputParser — AIMessage → 文字列
パーサーなしだと response.content で文字列を取り出す必要があるが、StrOutputParser を使うとそのまま文字列として扱えます。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.language_models.fake_chat_models import FakeListChatModel
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは{language}の先生です。"),
("human", "{word}を説明してください。"),
])
llm = FakeListChatModel(responses=["説明します。"])
chain = prompt | llm | StrOutputParser()
response = chain.invoke({"language": "Python", "word": "リスト"})
print(response)
print(type(response))
CommaSeparatedListOutputParser — カンマ区切り文字列 → リスト
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.language_models.fake_chat_models import FakeListChatModel
from langchain_core.output_parsers import CommaSeparatedListOutputParser
prompt = ChatPromptTemplate.from_messages([
("human", "Pythonの基本的なデータ型を教えてください。"),
])
llm = FakeListChatModel(responses=["str, int, float, list, dict"])
chain = prompt | llm | CommaSeparatedListOutputParser()
response = chain.invoke({})
print(response) # ['str', 'int', 'float', 'list', 'dict']
print(type(response)) # <class 'list'>
まとめ
| パーサー | 変換内容 |
|---|---|
StrOutputParser | AIMessage → 文字列 |
CommaSeparatedListOutputParser | カンマ区切り文字列 → リスト |
他にも JSON に変換するパーサーなどがあるらしい。
Step 5: メモリ
ファイル: step5_memory.py
実行: uv run python step5_memory.py
LLM はデフォルトでは前の会話を覚えてません。そこで履歴をリストで管理して渡すことで文脈を維持させることができます。
MessagesPlaceholder
プロンプトテンプレートの中に「会話履歴のリストをそのまま差し込む場所」を作る仕組み。
ChatPromptTemplate.from_messages([
("system", "..."),
MessagesPlaceholder(variable_name="history"), # ← ここに history リストが展開される
("human", "{input}"),
])
コード
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.language_models.fake_chat_models import FakeListChatModel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, AIMessage
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは親切なアシスタントです。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
])
llm = FakeListChatModel(responses=["はじめまして!", "素晴らしいですね。", "なるほど。"])
chain = prompt | llm | StrOutputParser()
history = []
# 1回目
response = chain.invoke({"input": "こんにちは", "history": history})
print(f"AI: {response}")
history.append(HumanMessage(content="こんにちは"))
history.append(AIMessage(content=response))
# 2回目
response = chain.invoke({"input": "私の名前は田中です", "history": history})
print(f"AI: {response}")
history.append(HumanMessage(content="私の名前は田中です"))
history.append(AIMessage(content=response))
各ターンで LLM に渡される内容
1回目: [SystemMessage] + [] + [HumanMessage("こんにちは")]
2回目: [SystemMessage] + [HumanMessage("こんにちは"), AIMessage("はじめまして!")] + [HumanMessage("私の名前は田中です")]
履歴が積み上がっていくことで LLM が前の会話を参照できるようになります。
Step 6: ツール
ファイル: step6_tools.py
実行: uv run python step6_tools.py
LLM に「検索する」「計算する」などの外部機能を持たせる仕組み。
ツールの定義
@tool デコレータをつけるだけで LangChain のツールとして扱えるようになります。
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""2つの数を掛け算する"""
return a * b
# ツールの情報を確認
print("名前:", multiply.name)
print("説明:", multiply.description)
print("引数:", multiply.args)
# ツールを直接呼び出す
result = multiply.invoke({"a": 3, "b": 4})
print("結果:", result)
@toolで普通の Python 関数をツールに変換する- docstring が重要: LLM はこの説明を見て「どのツールをいつ使うか」を判断する
- LangChain がツールの名前・説明・引数の型を自動で読み取る
注意
FakeListChatModel はツール呼び出しに対応していないため、LLM がツールを自律的に選んで使う動きは Step 7(エージェント)で実際の LLM を使って確認していきます。API KEY 確認できれば動かせるので難しくはないです。
実際の LLM を使う準備(Gemini)
Step 7 以降はツール呼び出しが必要なので実際の LLM を使う。ここでは Gemini を使います。
Googleアカウントがあれば使えるんで多分苦労はしないはず。
API キーの取得
aistudio.google.com にアクセスして「Get API key」から発行する。無料枠あり。
パッケージのインストール
uv add langchain-google-genai
動作確認
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-flash-lite",
google_api_key="ここにAPIキー",
)
response = llm.invoke("こんにちは、自己紹介してください")
print(response.content)
注意点
- 学習用なので API キーは直接コードに書いているが、コミットしてはいけない 絶対に
- 使えるモデルは https://ai.google.dev/gemini-api/docs/models で確認
- モデルによっては無料枠が 0 のものもある(その場合 429 エラーになる)
Step 7: エージェント
ファイル: step7_agent.py
実行: uv run python step7_agent.py
LLM が「ツールを選ぶ → 実行結果を見る → 最終回答を出す」というループを自律的に回す仕組み。
エージェントの動き(手動版)
仕組みを理解するため、まず手動で同じことをやりましょ。
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, ToolMessage
@tool
def multiply(a: int, b: int) -> int:
"""2つの数を掛け算する"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""2つの数を足し算する"""
return a + b
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-flash-lite",
google_api_key="ここにAPIキー",
)
llm_with_tools = llm.bind_tools([multiply, add])
tools_by_name = {"multiply": multiply, "add": add}
messages = [HumanMessage(content="3かける4はいくつですか?")]
# 1回目: LLM がツール呼び出しを決める
response = llm_with_tools.invoke(messages)
messages.append(response)
# ツールを実際に実行
for tool_call in response.tool_calls:
selected_tool = tools_by_name[tool_call["name"]]
result = selected_tool.invoke(tool_call["args"])
messages.append(ToolMessage(content=str(result), tool_call_id=tool_call["id"]))
# 2回目: ツールの結果を踏まえて LLM が最終回答を返す
final_response = llm_with_tools.invoke(messages)
print(final_response.content)
処理の流れ
[1] ユーザー: 「3かける4はいくつ?」
[2] LLM: 「multiply(a=3, b=4) を呼んで」 ← ツール呼び出しを返す
[3] アプリ: multiply を実行 → 12
[4] LLM に 12 を渡す
[5] LLM: 「3かける4は12です。」 ← 最終回答
自動版(create_agent)
上の手動ループを create_agent が自動でやってくれるのです。
from langchain.agents import create_agent
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""2つの数を掛け算する"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""2つの数を足し算する"""
return a + b
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-flash-lite",
google_api_key="ここにAPIキー",
)
agent = create_agent(model=llm, tools=[multiply, add])
result = agent.invoke({
"messages": [{"role": "user", "content": "3かける4はいくつですか?"}]
})
for message in result["messages"]:
message.pretty_print()
pretty_print() を使うと各ステップ(Human → AI → Tool → AI)が順に表示されるはず。
Step 8: RAG(Retrieval-Augmented Generation)
ファイル: step8_rag.py
実行: uv run python step8_rag.py
LLM が知らない情報(社内ドキュメントや最新情報など)を、外部から検索して LLM に渡す仕組み。「参考資料を見ながら答える」イメージ。
これが用途としては多いんじゃないかなぁ。
流れ
1. ドキュメントをベクトル(数値)に変換して保存
2. 質問が来たら、質問と似ているドキュメントを検索
3. 検索結果を LLM に「これを参考に答えて」と渡す
4. LLM が回答を返す
必要なパッケージ
uv add numpy
InMemoryVectorStore のコサイン類似度計算で必要。
コード
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
API_KEY = "ここにAPIキー"
# 1. 知識源となるドキュメント
documents = [
Document(page_content="LangChain は LLM アプリケーションを開発するための Python フレームワークです。"),
Document(page_content="Python は1991年にGuido van Rossumによって開発されました。"),
Document(page_content="uv は Astral 社が開発した Python パッケージマネージャで、Rust で書かれており非常に高速です。"),
]
# 2. 埋め込みモデル(テキスト→ベクトル変換)
embeddings = GoogleGenerativeAIEmbeddings(
model="models/gemini-embedding-001",
google_api_key=API_KEY,
)
# 3. ベクトルストア(ベクトルの保存先)
vectorstore = InMemoryVectorStore.from_documents(documents, embeddings)
# 4. 質問
question = "uv について教えて"
# 5. 関連するドキュメントを検索
retrieved_docs = vectorstore.similarity_search(question, k=1)
# 6. LLM に渡して回答を生成
prompt = ChatPromptTemplate.from_messages([
("system", "以下のコンテキストを参考に質問に答えてください:\n{context}"),
("human", "{question}"),
])
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-flash-lite",
google_api_key=API_KEY,
)
context = "\n".join(doc.page_content for doc in retrieved_docs)
chain = prompt | llm | StrOutputParser()
response = chain.invoke({"context": context, "question": question})
print(response)
用語
- 埋め込み(Embedding): テキストを数値ベクトルに変換すること
- ベクトルストア: ベクトル化されたデータの保存先
- 類似度検索: ベクトル同士の近さを計算して関連するドキュメントを見つけること
なぜ RAG が役立つのか
LLM 自身は学習時点の知識しか持ってません。専門的な知識は皆無と考えていいと思います。社内ドキュメント・最新情報・個別の事実などは知らないのです。
RAG を使うことで知らなかった情報を学ばせる事ができるのです。
「LLM の言語能力」と「外部の最新・固有情報」を組み合わせて回答を生成してくれるようになるのです。
あとがき
ざっと基本的な機能をさらった感じですかね。思ったより記事として長くなった。
コード自体はだいぶ短く抑えられるんですねぇ。なかなか便利だと思います。
メモ書きをベースにしているので不足部分はあるかと思います。そのうち色々加筆するかもしれん。
あとはもう少し実践的な使い方とかもまとめていきたいですね。
一旦はこんな程度であしからず。